
Next Token Prediction is a Fundamental Function of the World
Building blocks


All our knowledge has its origins in our perceptions.
-Leonardo da Vinci
As we've talked about in previous posts, a core tenet of AI is the ability to encapsulate knowledge. AI models need to be able to create an understanding of the world in order to make good predictions and high quality outputs. These high quality outputs are the result of AI models chaining together lots of small, sequential predictions. For large language models, this is called next token prediction. However, this concept is pervasive in different forms, not just with language. The predicting of the next token, or next state, is a fundamental way that entities navigate the world. By predicting what might come next, a mind begins to form an understanding of the world through the building of cause and effect relationships. Here we'll walk through the strength and universality of the next token prediction concept.
For those unaware, let me explain what next token prediction is. A token is a pre-defined unit. In a language model that could be a word, part of a word (think 's' at the end of a word), or multiple words (such as 'and the' or 'lives in'). We call them tokens because they are a combination of standard and non-standard units that make up the structure of the data. When modeling a sequence, such as a sentence, constructing that sequence is most easily modeled in a linear fashion. This means that future tokens are influenced by previous tokens. Next token prediction takes the sequence as is known up to a current point and then predicts the next token. For language generation, this is done in what is called an 'autoregressive' manner, where the outputs of the model are fed back into the model to keep predicting/generating additional tokens until you have a sufficient response. It looks like this:
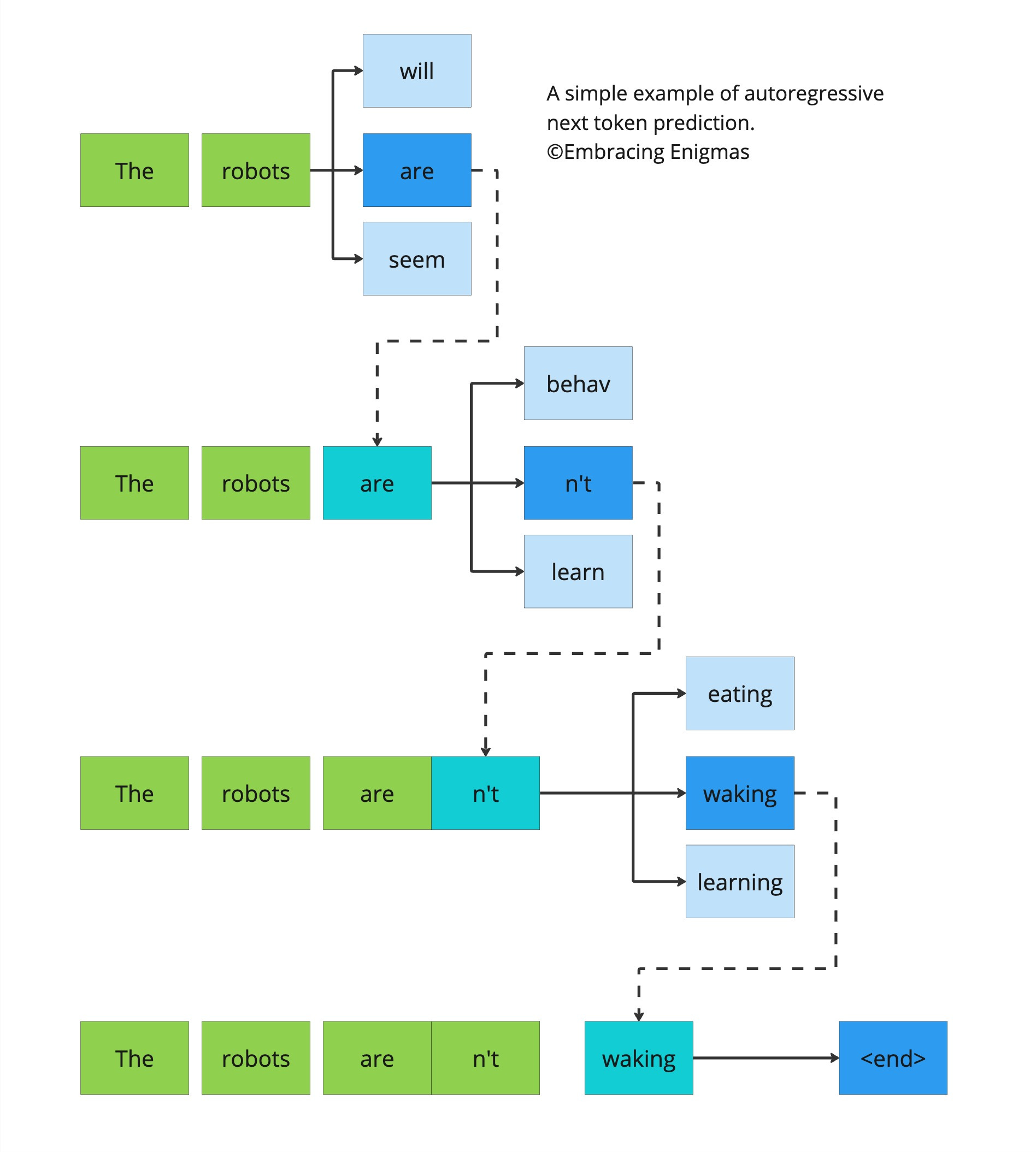
Figure 1. An example of next token prediction. Selected possibility in dark blue with other possibilities in light blue.
When ChatGPT first came out, a lot of people were saying "it's just a next word predictor". I don't know if I hear anyone saying that now. What people didn't or don't understand is that in order to be able to successfully predict the next word or token well, a model needs to have a superb understanding of the structure and environment it has been exposed to. If inherent structural understanding wasn't there, if knowledge wasn't encapsulated well, predicting the next word or token would fail spectacularly.
This is even more pronounced in multimodal models. A lot of people are just coming up to speed on multimodal models. Perhaps you are seeing language shift from using LLMs (large language models) to LMMs (large multimodal models). What you may not know is that they are pretty much the same techniques. One was trained solely on language which is single mode embedding space, and the other uses multiple modes and thus a multi-modal embedding space. The key difference is in adding the ability to ingest and align different modes of input (text, video, audio, images, etc.). In order to align these different modes, we create combined embedding spaces and perform a version of next token prediction.
A token can be anything. Most people think in terms of language because it's what they have been exposed to, but a token can be anything. It can be a frame, an image, an audio clip, a state, a molecular position, a force, etc. Think otherwise? Google used the same methods that large language models use in predicting the next word to create a foundation model that can predict the next step (actually multiple steps) in a time series. A generalized model to predict the next value of any time series. Temperature. Commodity prices. Public sentiment. Sensor readings. Consumer purchases. Anything. Why does it work? Because they treat values in a window of time as a token and apply typical transformer methods. And then Salesforce did it with Moirai and then Amazon did it with Chronos.
Using time is helpful to understand why next token prediction is a fundamental function of the world. Next token prediction has been around for a long time, but often we've been referring to it as something else. Whenever you have a simulation to model a physical process - a car crashing into a wall, fluid moving through a propeller, a chemical reaction, a manufacturing process, a basketball tournament prediction, etc. - you need to run it step by step. Why? The state of one step informs the conditions for the next step. Thus, computation can only happen sequentially. Both because you can't solve it all at once - that's why you're running the simulation - and because you need to flow through time. The flow of time controls the order in which a sequence of tokens or states can occur.
Let's build some more intuition for next step prediction by looking at entropy. How does entropy correlate with the flow of time? Entropy only moves in one direction - more disperse. Entropy creates irreversible processes. That is, you cannot go from an egg on a frying pan back into an uncracked egg. Instead, you can only go from an uncracked egg to a cracked one in the frying pan. This process is sequential. When you tap an egg on the edge of the frying pan, it will crack. We know this because we've built up knowledge of the world and thus know when a certain sequence is caused by an initial action. In fact, if you were unwittingly given a wooden egg, you would be confused when you went to go make your omelette. Consequently, we need to realize that predicting what will happen next, which really is what next token prediction is, requires an understanding of how the world works.
A physical model has an understanding of the environment it is modeling, defined mostly by physical equations. That same understanding is how your body is able to move deftly through the environment, acquire resources, and keep surviving. By understanding what has come before, we understand what may come in the future. This process is learning. This is why next token prediction is a fundamental function of the world. It is how we experience the universe and our understanding of how it works. We use that understanding to create products and infrastructure for the world around us. When surprises or mispredictions happen, that too induces learning. Models learn and keep improving. We keep improving. Any the universe carries on.