


People Don't Care How Good Your Model Is
They care if it solves their problem


A problem well stated is a problem half solved.
-John Dewey
People don't care how good your model is. They don't care if it's 99%, 95%, 70%, or 52% accurate. While you might fret about improving your model metric, the actual numbers don't matter. Then what do people care about? People care if your model solves their problem. People buy solutions.
That's a central tenet of technology that a lot of technologists don't understand. Most people don't buy technology for technology's sake, they buy a technology because it is the solution to a problem they have. Frankly, they don't care how it does it, as long as the technology meets their requirements or improves their current state.
Don't get me wrong, model metrics are important. As machine learning practitioners we are trained to find the best metric to use for a given problem along with different ways to optimize that metric. Improving that metric means a better performing model, which means the model is much more likely to be useful. However, after a model is finished, it will either be a product or packaged into a product. At that point, the performance of the model is a number on the spec sheet. After that, people will trial and test the product to see if it meets their needs.
Autocorrect
Let's take next word prediction on mobile phone keyboards, which has been an interesting area for understanding how model accuracy translates to problem solution. This technology has greatly improved over the years (and eventually turned into `autocorrect`) but when next word prediction came out, people were on the fence as to whether they should use it. Why? It usually wasn't good enough. You even saw articles like this asking if we should end autocorrect altogether. What if I told you that when it first came out autocorrect was ~90% accurate. You might think that number was good, right? Unfortunately, ~90% accuracy means 1 in every 10 words is wrong. If the average text is around 20 words (see Figure 1) that means two of them will be wrong. Enough to completely throw off the meaning of a message with so few words. At 95% accuracy you're at 1 wrong word in every 20 words and at 99% accuracy you're at 1 wrong word in every 100 words.
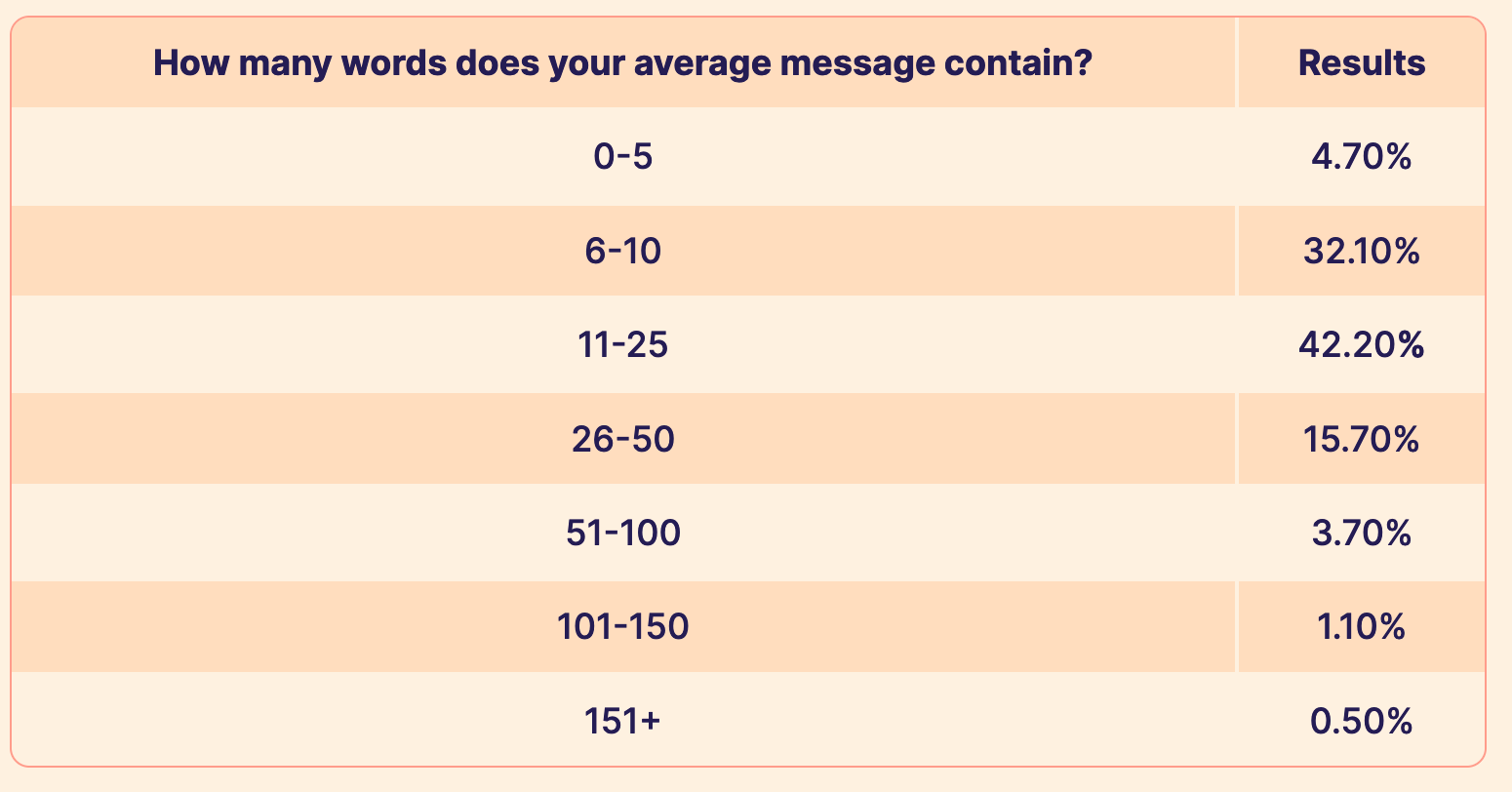
Figure 1. Average word length of text messages. Taken from here.
Somewhere in that range of 95%-99% accuracy, people started to accept next word predictors. And that's the thing - it was a range. What accuracy worked for some people didn't work for others. If you were a fast texter with normal word choice, you were more likely to accept a lower performance rate because you were gaining an improved, faster user experience. Conversely, a slower texter with a deep vocabulary was less likely to use next word prediction because they would spend more time correcting mistakes. Neither of these texters really cared what the actual model performance metric was, they just cared if it improved their texting experience.
LLMs
Here's another more recent example. Anthropic just announced that their LLM Claude can handle 100k input tokens which is about 75,000 words or 150 pages. Claude is large enough that it can read all of the Great Gatsby in an instant. Who does this matter to? If you are generating 15-word paid search ads, the extra context length is probably irrelevant. If you're a lawyer that needs to create understanding from thousands of pages of legal briefs, it helps but doesn't get you anywhere close to where you would like. The person that wants this extra context length is someone who was hitting token limits from advanced prompt engineering coupled with vector search lookups in order to add info into their prompt. Different people have different problems and different needs.
Alternatively, you may not know that before it powered ChatGPT, GPT-3 had been around for three years. In fact, while the ML community was excited by GPT-3, OpenAI made comments that they were having problems getting people to use GPT-3. So what changed from GPT-3 to ChatGPT? Yes, they made some performance improvements through RLHF but more importantly, they made a user interface that was much easier for the regular person to use. Think about that. The main reason the GPT model became useful was more about the interface than the actual model performance. Even with all of the imperfections and failures of ChatGPT, people still love it and find ways to make it useful despite how often it gets things wrong.
Solution Mindset
To be successful in machine learning, your focus needs to modulate back and forth between the mechanics of the technology and the human-centric problems it can solve. Creating a successful model means focusing on the real-world impact it has on users. Reaching impact requires formulating the right question which requires asking lots of questions and framing the problem from multiple directions. With the problem correctly formulated, you can link model outcomes to business outcomes to determine the necessary level of model performance.
At the same time, realize that there is a user adoption curve based on their tolerance for errors which correlates to different levels of model performance. The range of problems users have also enables your model to be used in a range of solutions. Repurposing a model or applying it in a different way enables you to discard prior performance requirements and focus on solving the new problem sufficiently. Basing your mindset around great solutions is not about abandoning the pursuit of technological excellence, but rather, about aligning this pursuit with the needs of the users. By focusing on the user's problems and how to solve them, models become a tool for making people's lives easier, more efficient, and more enjoyable.