


The Hyperbolic Rise of AI Terminology
What constitutes AI?


As the world is being taken by storm by generative AI, there's also a lot of confusion about what AI is. Over my career, I've watched as terms around AI have been inflated and hyped. I think now is a good time to talk about what qualifies as AI and what does not, along with how terminology becomes overhyped, especially when a lot of people in cryptocurrencies are switching over to generative AI.

Definitions
Let's start with defining some terms that you may or may not have heard of.
Algorithms: A set of instructions used to solve a problem or perform a computation.
Statistics: A discipline concerned with the collection, organization, analysis, interpretation, and presentation of data.
Machine Learning: Models that combine both algorithms and statistics that use data to improve performance on a set of tasks. Typically these models improve over time as new data or feedback is gathered, hence the models 'learn'.
Neural Network: A type of machine learning model that uses nodes inspired by animal brains to create a probabilistic weighting function between the designated input and the desired output.
Deep Learning: A subset of machine learning focused on using large neural network models with many layers combined with large amounts of training data.
Artificial Intelligence: A machine that can perceive, synthesize, and infer information. Current approaches use deep learning along with other machine learning techniques.
Artificial General Intelligence: An intelligent agent that can understand or learn any abstract, intellectual task a human can. When people refer to AI in movies, fiction, or regular conversation, this is typically what they are referring to.
Term Hype
These terms around AI seem pretty clear, especially if you have a technical background, so where does the confusion come from? I think a lot of confusion happens from misunderstanding subsets of different fields as completely new things. For instance, if you don't know that deep learning use neural networks and both deep learning and neural networks are types of machine learning techniques, you might be inclined to think that machine learning, neural networks, and deep learning are three very different things. You might even think you need three distinctly different systems in order to compete when in actuality you just need one. To add to the confusion, people have varying definitions of these terms and then relay them second hand to others. All of this confusion on terms and topics has enabled a lot of vendors to take advantage of people who do not understand the differences and have a big fear of missing out. What I've seen in my career is lot of hyperbolization of terms to make claims that a system is using ‘X’ technology in the hopes of convincing others that their system is state of the art when it might actually be based on simple methods.

Figure 1 - The increasing hypebolization of modeling terms over time
What has this looked like? As shown in Figure 1, regardless of what was actually being used to operate a system, the term in red was what was stated in the communication as the underlying technology since it was the hot, new thing at the time. For instance, if your system used “lowly” statistical models that made massive business impact but the zeitgeist was raving about neural networks, you would claim your system was using neural networks. In a world where people are confused on topics and lack a depth of knowledge, these claims are very hard to verify.
As the hype machine increases, it makes it hard to understand what innovation is real and what's being faked. I've seen a lot of this behavior in examples like the app Magic when it first came out. Magic was an app that tried to be Uber for everything through texting a certain number. It was really humans pretending to be an AI pretending to be a human. This was a common theme in the mid to late 2010’s timeframe when chatbots were the hot thing. While it wasn't actually AI, it was implied AI without the technical accomplishments.
A Case Study in Hyperbolic Terming: Cognitive Computing and Watson
Over a decade ago, IBM Watson dazzled the world with its ability to win the game show Jeopardy. Watson was an AI system mainly focused on information retrieval. IBM spent several years on top of a decade of research along with hundreds of millions of dollars to build the Watson system. Watson was based on a lot of high-quality research particularly around natural language processing (NLP) and knowledge representation. Watson combined a lot of machine learning techniques in such a way that it could complete the more general task of question and answer. In some of the papers used as the basis for Watson, the term for these general technologies was called cognitive computing but it was really just a renaming of AI.
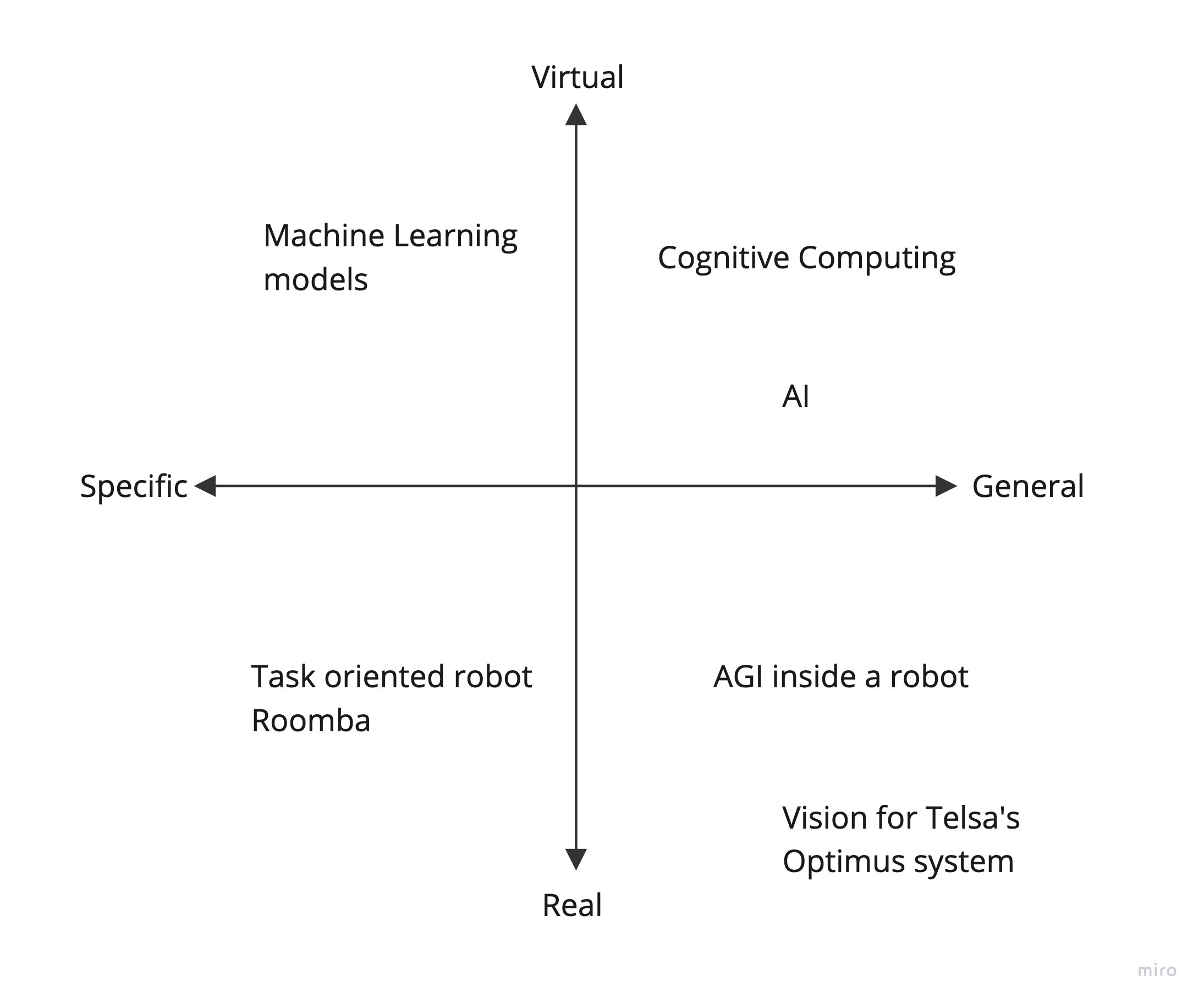
Figure 2 - A framework for different types of intelligence systems
What is cognitive computing? Let’s examine Figure 2 a bit. We have two axes, Virtual-to-Real, and Specific-to-General. The Virtual-to-Real axis denotes where a system acts, either within computers and data (Virtual) or within the physical world (Real). The Specific-to-General axis denotes if the system is geared towards a single task (Specific) or many, different tasks (General). Looking at these axes give us four quadrants.
In the top left, we have the realm of the Virtual and Specific. This quadrant is for very narrow tasks that take place through computation and data. Here is what would be considered your typical machine learning models such as home price prediction, identifying the content in a photo, movie recommendations, etc.
In the bottom left, we have the Real and Specific. This quadrant encompasses your typical task-oriented robot like a Roomba. It is an intelligent system whose operations are solely geared towards cleaning your floor.
In the bottom right, we have the Real and General. This is an AI or AGI that operates within a robot and is the current AI holy grail. When people think of robots taking over, those live in this quadrant. The closest thing have at the moment is probably Tesla’s Optimus system, but that’s still a long way off.
In the top right we have the Virtual and General. Here live most AI applications that can solve many different types of tasks in the world of data and compute. Some academic papers dubbed this region cognitive computing in the late 90’s/early 2000’s because they felt it mimicked how the brain operated while still trying to define various areas of AI.
Given that context, what happened next? Well, people were blown away by Watson being able to win Jeopardy and IBM needed to recoup their investment in the technology. So, IBM spent an additional hundreds of millions of dollars to form a team of business and marketing folks to figure out how to sell and where they could apply this investment heavy technology. All of a sudden, ads for Watson were everywhere, trying to be used in every industry! There was Watson for taxes, for healthcare diagnosis, for building codes, to teach, for weather forecasting, for advertising, for fashion, and the list goes on. Anyone who had actually played with Watson knew that it could not do all of these tasks out of the box, so engineers had to build new machine learning augmentations to solve the use cases in these different areas. However, saying Watson was using only machine learning in the 2014-2017 time frame was not very sexy. What term, then, did they settle on? You guessed it - cognitive computing. IBM chose to create a hype term for their technology that was a collection of machine learning models applied to new areas. This hype machine caused a massive amount of demand until people used the technology (myself included) and were greatly unimpressed.
Why? Watson was really built and honed for the specific task of answering questions on Jeopardy. It was only on the border of being a general purpose virtual intelligence. IBM believed they could fake the act of being a fully general system applicable to any field by building new modules that were actually a collection of Specific-Virtual models. Put another way, Watson rarely was able to leave the realm of the Virtual and Specific, except in some special knowledge representation circumstances. This meant that the Watson team really couldn’t extend their technology like they thought and their claims of grandeur fall flat. Which is why we now have a New York Times article asking “Whatever Happened to IBM Watson?”. In my experience, when you use hyperbolic terms about your technology, you’re likely not going to get the outcome you want in the long term. Instead, you should focus on what value your system provides, since that is what buyers really care about.
What qualifies as AI?

Figure 3 - AI techniques and their hierarchy
After reading through this, you might be your asking yourself “so what really qualifies as AI?”. Let’s look at our definition above.
Artificial Intelligence: A machine that can perceive, synthesize, and infer information. Current approaches use deep learning along with other machine learning techniques.
Based on this, the systems you’ve likely interacted with or seen that are true AI systems are:
GPT-3
ChatGPT
DALLE-2
Stable Diffusion
AlphaGo
Why? Because these AI systems are encoding large amounts of knowledge representation based on natural language processing or visual perception. Anything else is likely a machine learning model that is used to make automated decisions based on patterns in data with some feedback mechanism. Looking at Figure 3 we can see that part of AI is machine learning of which, part of machine learning is neural networks of which, part of neural networks are deep learning systems. The relationships do not necessarily go in the reverse direction.
I hope this clears up some of the confusion around what AI is and gives you some hesitance around the hyperbolic rise of AI terms. If you see terms escalating, it’s a good idea to step back, ask what’s going on, and investigate the methods that are actually being used behind the claims.