


The Tic-Tac-Toe Dilemma
Why automation is hard, or the last mile problem in AI


The longest mile is the last mile home.
-American Proverb
Note: There’s a lot of photos in this post and you might have to click ‘view entire message’ in your email to see everything.
I get a fair number of questions about what makes building AI systems tricky. The answer boils down to, automation is hard because you can't intervene while the process is operating. When a process becomes automated, the acceptable rate of error tends to decrease because if something goes wrong, nothing can be done. This means you have to consider and account for a lot more edge cases and low frequency events. Why? Those are the areas that tend to drive error rates after meeting a baseline level of performance.
When we look at the state of AI at the time of this writing, AI has a variety of areas where it excels while also having areas where it produces many unexpected errors. The difficulty in discerning where this will happen is something
calls the Jagged Frontier. I want to walk you through an example to show why automation is difficult, even for simple things. As we go through the example, think about the steps you might take to verify that the output is correct/sufficient strictly through algorithms and code, not through manual intervention. What process would you create? How would you know that verifications are sufficient? How would you know when to start over? How would you test that your commands give the right output?Note: This article stems from an actual attempt I made to have ChatGPT create a photo of a tic-tac-toe game from an unrelated piece I was writing. I got so frustrated with the process that I wrote this instead.
The Setup
Let's try something simple. When talking about large language models and multi-modal models most people focus on what the models don't know or the extent of their knowledge. For this example, we want to work on something LLMs and AI definitely should know and be able to easily perform. Let's have ChatGPT create an image of a viable tic-tac-toe game. The game should be familiar to nearly everyone and there is an extensive Wikipedia page on tic-tac-toe which is used in the training data for ChatGPT, meaning the knowledge should be embedded. This task should be simple and straight forward, right? Right??
The Test
Conversation 1
Ok let's start simple and straightforward.

Not bad. At a quick glance it seems all good but after staring at it, the double win for X's seems off. While technically possible, it is extremely unlikely that ever happens. Let's change it to have a few empty spaces.

Huh? It thinks it's only filling out four spaces but instead it made a 4x4 grid. Time to have ChatGPT adjust.

Well, that's worse. For some reason, I get the impression that ChatGPT is adding words to the image to emphasize its correctness despite being very confident that it has a 3x3 grid, which it most definitely does not.

At this point I asked it to verify and it identifies the need to have a "3x3 grid with exactly nine spaces with only 4 filled (two X's and two O's)". That requirement is correct but the image is not correct as we're back to a 4x4 grid with 16 markers in place. Let's have it think through the problem more closely.


WTF? The written logic is flawless. But now there's a 4x6 grid labelled "3x3". There's a massive disconnect between what's written and what's generated. I'll give it a few more attempts to correct itself.



At this point it's pretty clear that ChatGPT won't break out of its flawed loop. Let's start a new conversation in case any context of flawed image logic is carrying over throughout the conversation.
Conversation 2
Ok. Let's start a new conversation. Based on our previous experience, perhaps it would be good to be a little more specific on how the board should look.

Ok, fair. We didn't specify we wanted a picture and we got ASCII art of a tic-tac-toe board. Let's have it turn that text based image into an actual picture.

C'mon man! So close yet so far. Not only does the board not replicate what ChatGPT originally laid out but it the setup is also impossible in a regular tic-tac-toe game. Let's try having it resolve and remake what was originally laid out. This may take a bit.




At this point, it's pretty clear ChatGPT is going to fail again at drawing a legitimate tic-tac-toe setup or even adhere to what it calls out by its own logic. Let's try a new conversation and start over.
Conversation 3
Ok. Let's go back to the beginning and hope that the random number generator gods are kind to us.
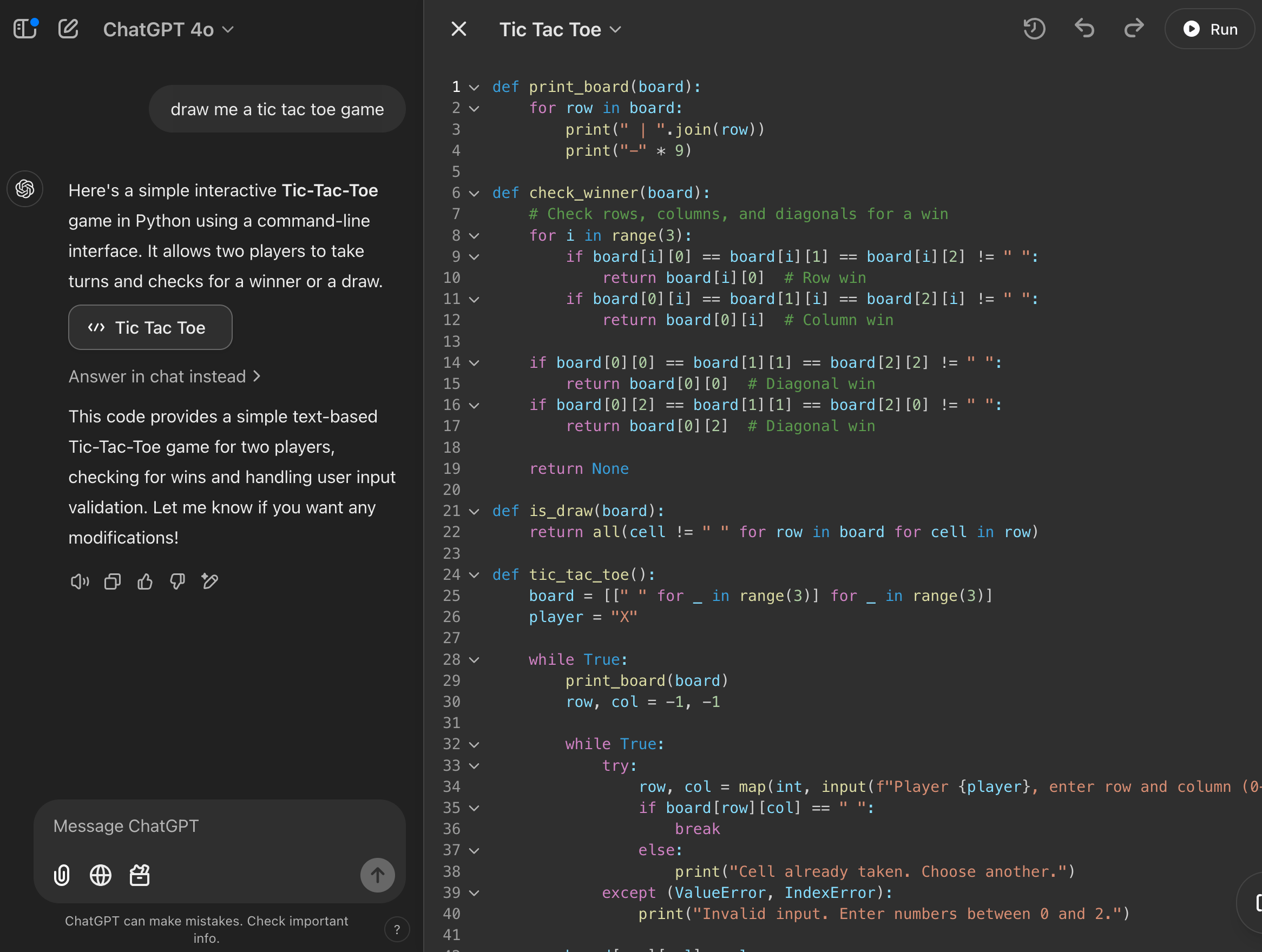
Uhh what? I asked it to draw a tic-tac-toe game and received python code that generates a tic-tac-toe game. ... While admirable, that's still going to end in ASCII art. Let's click that "Answer in chat instead" button to change how ChatGPT responds.Ok more ASCII art. If you see that "2/2" that's the second version of the answer output. The first being the code. Let's see if we can get a picture out of this.
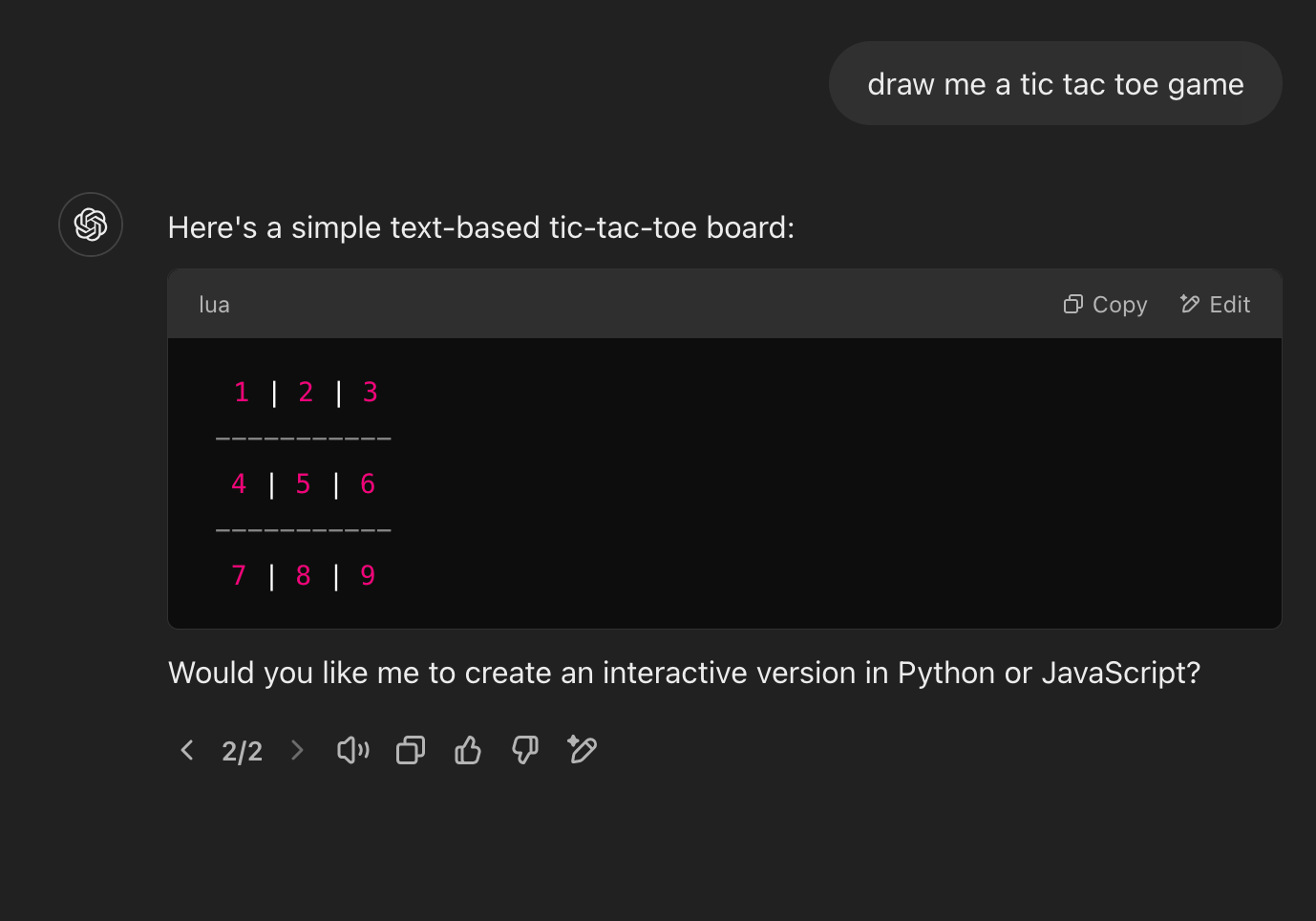
Ok more ASCII art. If you see that "2/2" that's the second version of the answer output. The first being the code. Let's see if we can get a picture out of this.

Hooray!! We got something. Granted it's still showing a double win and another unlikely outcome but this seems more probable. Not my favorite style but it's valid. After spending over 30 minutes to get an acceptable picture of tic-tac-toe, I finally got one.
What Happened?
We set out to do something demonstratively simple and it took a lot of work to get there.
To get to the end state required a lot of steering and a lot of retries, which probably doesn't surprise anyone who has used these generative AI models extensively. However, I still think it will be surprising to many that the output doesn't magically happen. Why did this happen and what are the implications? There's three main gaps to address:
Communication
Coherency
Verification
Communication
When you make a request to an AI, or really any individual, how do you know they will interpret it the way you intended? If you ask ten people to draw an image of a horse, you'll get ten different images. If you added more details - color, breed, posture, age, etc. they will still all be different. Working with AI is no different. There will be differences between your expectations and what happens. This is a difficult problem about how one articulates and actualizes desire.
Think about when we asked ChatGPT to "draw a tic-tac-toe game". Even if we care little about how the image looks, we still have a lot of unsaid assumptions. We want a game position that is legitimate. We expect the board to be the correct 3x3 grid. We expect that X's and O's are used. We expect these unsaid assumptions to be reflected in the "tic-tac-toe game" but there is no guarantee that the understanding is the same. We would expect these assumptions to be known since the information about the game is included in the training data but that's a different disconnect.
When communicating with AI you need to have the right level of specificity. If you have stringent standards or are too broad or too vague in your request, it is likely to not produce what you want. If you are too specific, it can over constrain the model and cause it to repeatedly fail in unexpected ways or even do something that isn't possible. To see this for yourself, try asking an AI to move part of an image 10 pixels to the left.
Coherency
Looking back through the three conversations, it's clear there is a difference between the textual side of the model and the image side of the model. While the text version was able to understand and relay what was needed correctly (4 spots filled, meaning 2 X's and 2 O's), the model was unable to generate an image aligning with that understanding.
In part, this arises from embeddings, a key technique used by ChatGPT and DallE. Current advanced AI models make heavy use of embedding models. This reduces the number of variables on which a model has to operate. This has the additional effect of acting like a compression algorithm, whereby you have the potential to lose information in its application. Depending on the current methodology, the models could be using one unified embedding model between images and text, or separate embedding models that are unified later (the original DallE used this). In either case, it's clear that within the embeddings counts and position are not tracked well and information is lost in translation.
Verification
Each time we asked for changes, the model confidently returned that it had accomplished the task and why. Yet, almost every time it was wrong. I'm sure many of you have had similar experiences with people reporting to you. Current AI models lack good verification methods. We have seen techniques such as Chain of Thought that try to verify preemptively but there is never a guarantee. Alternatively, I've seen better success with people deploying multi-agent systems where one agent is the creator and another acts as the verifier. It's similar to how generative adversarial networks (GANs) work albeit without the training. However, even in a multi-agent system there can be gaps as the same models tend to have the same holes in them. If you were going to automate the verification of the outputs of a tic-tac-toe creation process, what would you do?
Why the Last Mile is Hard
A world moving closer to agentic AI is a world moving closer to large amounts of automation. When you automate a process, by definition you are foregoing intervention. This means you need to create a process that steers itself and can handle edge cases. If we consider the tic-tac-toe example, we needed to continuously intervene and guide the process, and even restart twice.
When prototyping, you can easily get to a 70-80% workable solution pretty quickly. This becomes pretty evident when playing with ChatGPT for a task. But people might not realize the active intervening they are doing. It's like how short form video algorithms (Tik Tok, Youtube Shorts, Facebook Reels, etc) seem so good. You forget the content you swipe past and focus on how every video you do decide to watch is worthwhile. Similarly, when working side by side with an AI, you tend to forget the little nudges or modifications you made because you were tracking on the right path. The ability to nudge or modify disappears when you fully automate a process with agents. The hard work comes in the last mile where you can't intervene.
The hard work is in making the process consistent and performant while adhering to a set of standards. If you want something vague, it works fine because your internal assessment function is low. If you want something specific, you need ways to determine if outputs are up to specification. The more specifications, the more complexity gets added to the system. The higher the complexity, the more places error can arise. All of this creates issues that need to be solved. When the issues aren't solved, a painful, error prone tool emerges. When they do get solved, magic happens.
For your first two cases, the problem lies not in ChatGPT (likely GPT-4o) misunderstanding your request or not communicating it. The problem is that there are two separate models at play:
1. GPT-4o, the LLM with which you're chatting, and which then turns your request into a prompt for DALL-E 3
2. DALL-E 3, the diffusion text-to-image model which receives the prompt from GPT-4o and then generates the image.
There are at least three compounding issues here:
1. Every time you ask ChatGPT to change the prompt, it will incorporate some of your requests into the DALL-E 3 prompt, potentially making it worse. You can trace all of this by clicking on the images in your ChatGPT conversation, and then clicking the little "i" icon at the top to see the exact prompt that ChatGPT gave to DALL-E 3.
2. This disconnect between the chat model (which understands what you want) and the diffusion model (which the chat model generates prompts for) introduces new issues. The more you focus on what not to include, the more attention ChatGPT will place on that item. For instance, if your first image had an elephant in the background, and you asked ChatGPT to "Please, I don't want any elephants," it would generate a new DALL-E 3 prompt, which would then include a line like this: "There should be absolutely no elephants anywhere in the image."
3. And this brings us to the final issue. Diffusion models don't respond well to negative instructions. They basically treat any tokens in the prompt as something to render. This is exactly why most tools typically include a separate "Negative Prompt" field (or a --no parameter in Midjourney). Simply including negative instructions in your prompt will actually make it more likely. Try writing "an elephant without a fedora" into most image generators, and I can almost guarantee you that you'll get an image of an elegant wearing a fedora (so you were better off not mentioning the fedora at all).
You can actually force a precise prompt in ChatGPT by writing something like this in the chat:
"Please generate an image with the following exact prompt: '[YOUR PROMP].' Do not modify or add to it in any way."
However, even if your prompt is perfectly written by ChatGPT and says something like "A tic-tac-toe board showing two crosses at the top and a circle in the middle." - DALL-E 3 (and even most modern models) don't have the capability to consistently render images with that level of nuance. Prompt adherence is getting better, but it's nowhere near as precise as you're aiming for in this scenario.