
Turn Down the Noise
Increasing the signal for better models


When you're focused, you don't hear the crowd noises, you only hear what you need to hear.
-Rudy Ruettiger
Noise. The bane of every modeler, parent, and decision maker. Noisy data reduces the signal that a model can pick up, leading to a less predictive model. In terms of data, noise refers to irrelevant or meaningless information that can obscure, distort, and interfere with the interpretation of that data. Noise arises from various sources, such as errors in data collection, measurement inaccuracies, or the presence of extraneous variables not relevant to the analysis. To better understand these issues, let's examine the impact that noise can have on modeling and different ways to deal with noise in data.
The Impact of Noise
Noise causes excess variance and errors. Think of it as providing false signal, that when unaccounted for, leads to misleading insights and interpretations. For instance, in computer vision it is routine to create synthetic data which is done by adding random distortions to the image to improve identification in low quality images. However, if those distortions are too "regular", a computer vision model can actually pick up on them. The model will make decisions based on the "applied noise" such that the model will hallucinate and pick up on objects that aren't there. This is because it has identified noise in the target image similar in type to what which was used in the training data.
One big issue with noise is that as you integrate or make data transformations, errors propagate and get accentuated. In machine learning, this might appear as spurious correlations that the models double down on. In physical sensing system, it results in the phantom appearance of things that are wildly impossible. That's why measurement calibrations are so important. Though even if you're highly accurate, small errors can add up depending on the scale you're working at.
Anyone that's dealt with sensors is very attuned to the need to identify and filter out noise and drift. In fact, this is such a big issue that the Android operating system adopted a technology called SensorFusion that combines information from multiple sensors to better measure the angle and position of an object. Over a decade ago, David Sachs gave a great talk about the issues sensors can have in trying to determine the angle and position of an object. I'll let David Sachs explain (at minute mark 23:22) how small amounts of noise from accelerometers can cause wildly inaccurate readings about the position of an object:
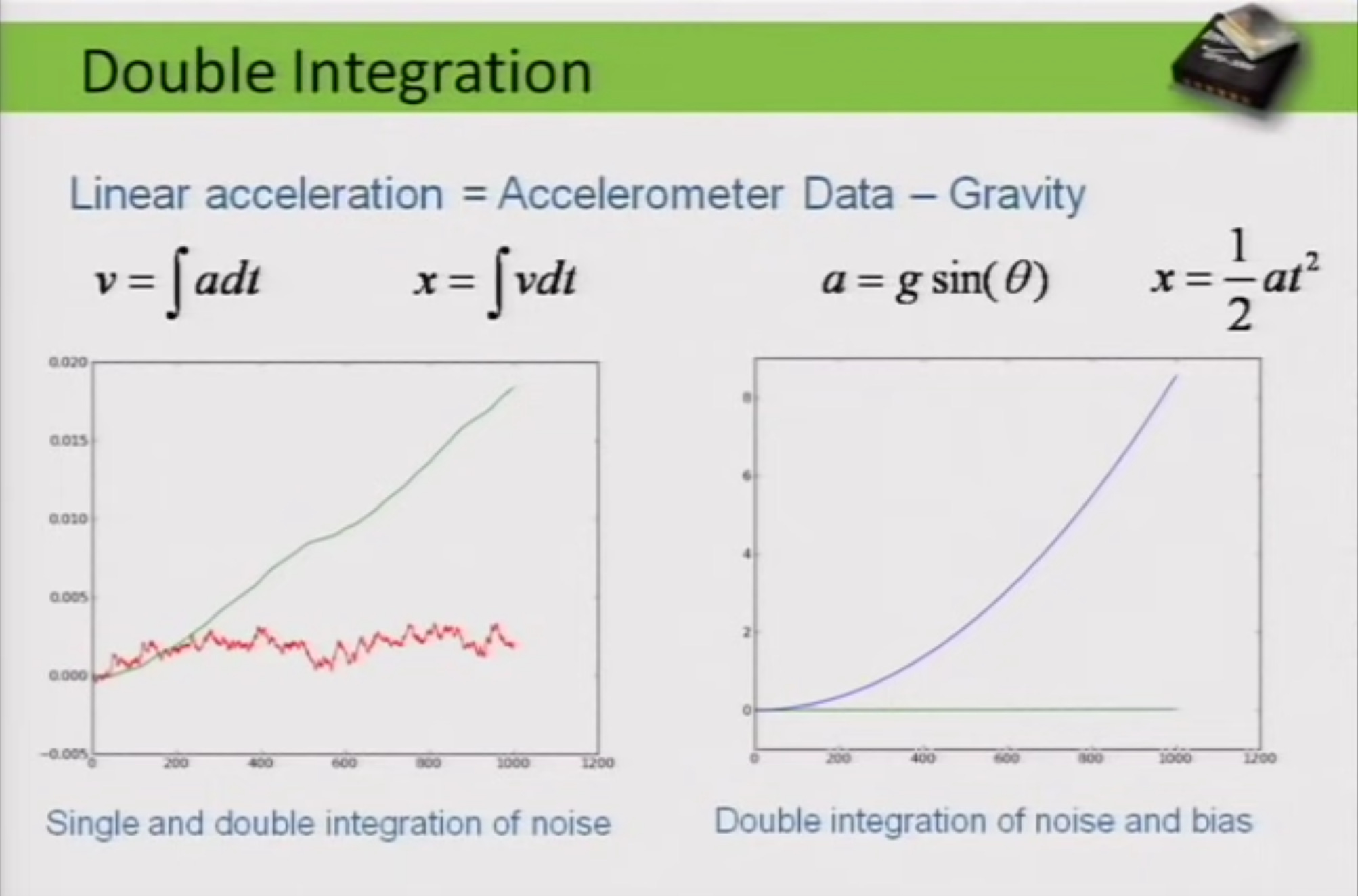
Figure 1. The impact of noise on integrating from acceleration to position.
So now we get to position. Accelerometers measure side to side movement, so can't you get position out of them? Well, it turns out it's really, really hard but let's talk about how that would work. So linear acceleration, which is what you want just my side to side, up, down, and forward-backward movement. You have to take the accelerometer data and you have to remove gravity, this is called gravity compensation. So once I've removed gravity, whatever's left is my linear movement, then you have to integrate it once to get velocity, integrated again to get position, that's your double integral.
Now if the first integral--a single integral creates drift, double integrals are really, really nasty, they create horrible drift. Here's a graph of it [the graph in Figure 1]. The red stuff is a single integral. You can see that random walk we talked about before, it sort of meanders off in some direction. And the green signal is a double integral. It's just taking off. Now, this is integration of noise. So you can see this is simulating an accelerometer. I'm holding it in my hand, not doing anything and it drifted off by 20 centimeters in one second. So I don't know. Is that good or bad? Actually, I think that's pretty good as you'll see in a second. But--so one second of drift, 20 centimeters of error. That's from integrating noise. But that's not the problem. Here's the real problem. The problem is remember back at the beginning of the slide when I removed gravity, well, I probably didn't do that exactly right. That's pretty hard to do that perfectly. So let's say I got it wrong.
Let's say I thought I was holding this thing at 37 degrees but I was really holding it at 38 degrees. So I screwed up my estimate of gravity by one degree. Well, now, I double integrate that. I get a parabola. So I'm double integrating a constant, right? Here's what that looks like. So for comparison, the green line at the bottom is the same as the green line in the graph on the left. Now, it just looks flat, right? So the new error is this blue curve, that's eight and a half meters of error in one second. So I was holding this for one second. I screwed up my orientation by one degree and I got drift of eight and a half meters. So you can see why it's really, really hard to do any kind of linear movement.
What can be learned from this? Making transformations on noise or taking action in the presence of noise, say in an automated pipeline, can result in large amounts of error in the absence of adequate compensation. In general, it's much better to measure what you want directly as opposed to through proximal measurements combined with data transformations. Unfortunately, sometimes all you have available is proximal measurements and you have to settle for large errors until methods improve.
Noise Reduction in ML Models
There are two ways to reduce noise - you can use techniques that remove or ignore noise, or you can modify the input data. Let's talk about the first one. There are many models and techniques that naturally reduce the impact of noise. A few of those methods are:
Bagging: Bagging takes random slices of the data and routes those slices to different sub models. This reduces the impact of any particular set of noise from inadvertently amplifying the signal too much.
Dropout: In neural networks, dropout is a method that will randomly turn off different neurons during training to make predictions more robust and ensure that neurons as a whole are not picking up too much on noise. Fun fact - you can use dropout at the time of inference to create a confidence interval on the prediction.
Mixture of Experts: These are an extension of ensemble models that have been applied to the latest transformer architectures. Different tokens are routed to different experts based on the current routing information inside each layer. This enables robustness to noise by creating learned filters of information.
All of these techniques work to reduce noise by randomly removing data that might be inadvertently used as a signal. Other methods look at changing time scales or hierarchies to obscure or cancel out the noise. For instance, in structural load testing, you measure the deflections of specific structural elements under a known load to determine if the elements have sufficient strength. In these situations, it's common for instrumentation to be able to take measurements at the second or sub-second level. However, doing so tends to create so much noise that it makes interpretation difficult. This noise is generated from various changes in the environment and electrical signals which are not part of the test. To combat this, measurements are taken on an hourly or multi-hour basis. The lower sampling rate has the benefit of removing noise from the interpretation. In a similar vein, when performing machine learning modeling look for techniques that work at different levels to remove the effect of noise that you might miss in your preprocessing steps.
Phi Project
The other way you can reduce noise is by removing the noisy data altogether. In statistical modeling, you might use outlier removal or binning. In time series data, this can be done with smoothing techniques. In more complex situations such as image processing or language modeling, you might go through and manually evaluate and remove low quality data. In all of these cases, the goal is to improve the signal available for interpretation and prediction.
It's with this in mind that the Phi project by Microsoft was born. The Phi project has an interesting objective - how small of a model can be created that performs as well as the largest and best performing models? Microsoft did this by focusing on creating the highest quality data set they could. They used vanilla transformer architectures and sought to create a data set that had the highest amount of signal possible so as to reduce the number of required parameters. They released their first model last year and were able to surpass GPT-3.5 performance on HumanEval with a model that was only ~1% the size (Figure 2). That's significant because transformer architectures currently have a scaling law where increasing the number of parameters increases the performance at a somewhat linear rate.
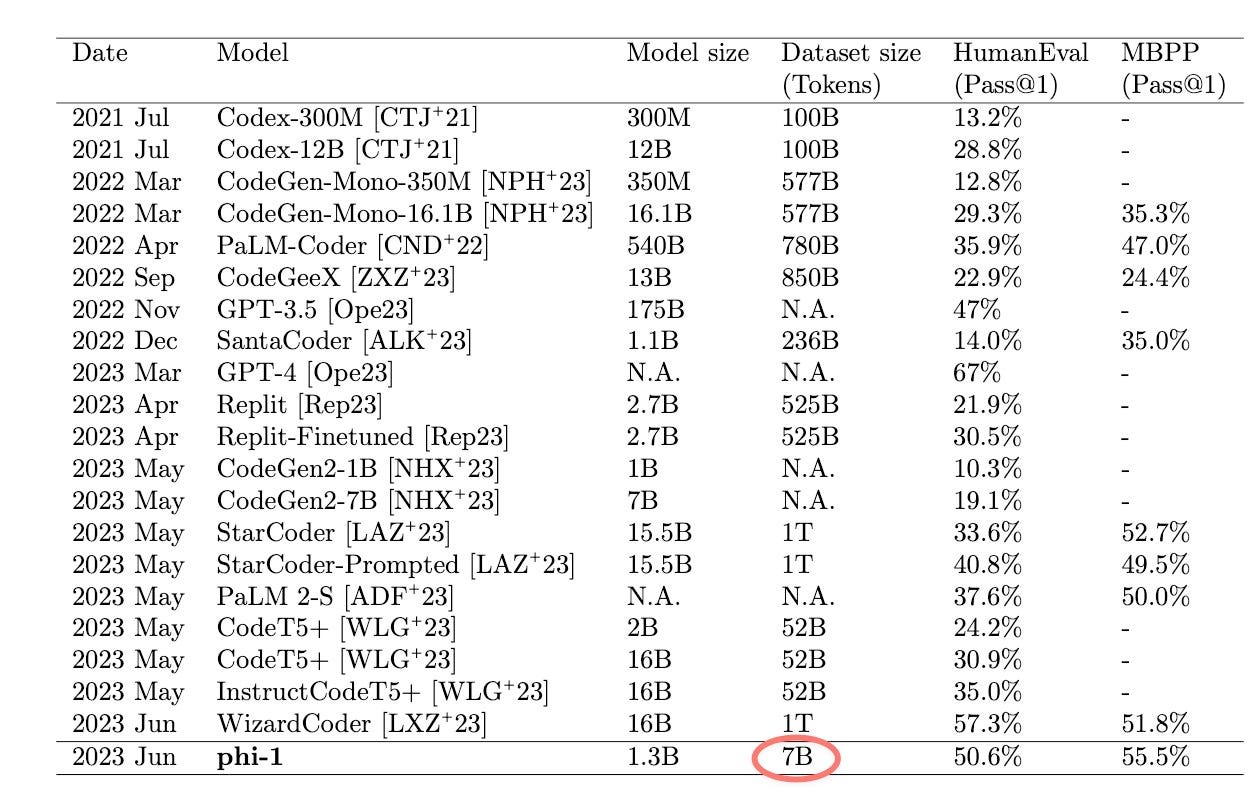
Figure 2. Initial results for Phi-1 vs other available models at the time.
Microsoft kept improving this project with the release of Phi-2 and recently released the paper and model for Phi-3. You can see how the Phi family of models performs against the family of LLaMA 2 in Figure 2. They scaled up the model size a bit for Phi-3 and improved their methods for both filtering and creating high quality data. Microsoft also scaled up their data purification methods as the training set size for Phi-1 was ~7B tokens and for Phi-3 it was ~3.3T tokens. About 3 orders of magnitude greater.

Figure 3. The performance difference between Phi and LLaMA 2. The y-axis is error (lower is better) and the x-axis is the size of the model in billions of parameters.
What's great about the Phi project is that it helps us identify the bounds of what's possible. At the same time, it shows a path forward to create better models without having to shove as much as possible into the largest model possible. I'm a believer that transformers will not be the final architecture that gets us to AGI and the Phi project helps show part of the reason as to why. Simultaneously, I've spoken to others in industry creating foundation models and they are able to see similar to better levels of performance when they reduce their data set size by an order of magnitude and filter for high quality data. That is, removing noise helps improve the signal that models can pick up on. This makes sense since as you can imagine, when you are cramming all the data created on the internet into a model, there's bound to be a lot of noisy and low quality data.
The most underrated and highest payoff task in machine learning and AI is manually going through the data. This serves two purposes. The first is to understand the data and where models make errors. The second is to figure out how to remove noise and make transformations to improve the signal to a model. In the quest to reduce model errors, seek to identify and remove areas of noise. When you turn down the noise, you turn up the signal.