


Examining the Moats for Generative AI
Or why you should think of advanced AI as a utility


I previously wrote here on Embracing Enigmas about how the coming wave of generative AI startups will use existing foundation models as a utility. Why is that the case? Let's look at the economic moats for the current foundation model proprietors that make it very hard for companies without deep pockets to create foundational models.
Computational Costs
Data Acquisition
Talent Cost
Computational Costs
One hundred seventy-five billion. 175,000,000,000. That's the number of parameters in GPT-3, which is the model that powers ChatGPT. For comparison purposes, the brain has somewhere between 86 billion and 100 billion neurons. Meaning GPT-3 has roughly double the number of parameters as there are neurons in the human brain. That's huge! But large language models just keep getting bigger and bigger. Google's PaLM model has 540 billion parameters (~5x the size of the human brain). You can see the model size growth in Table 1 below (note the last column is in millions):
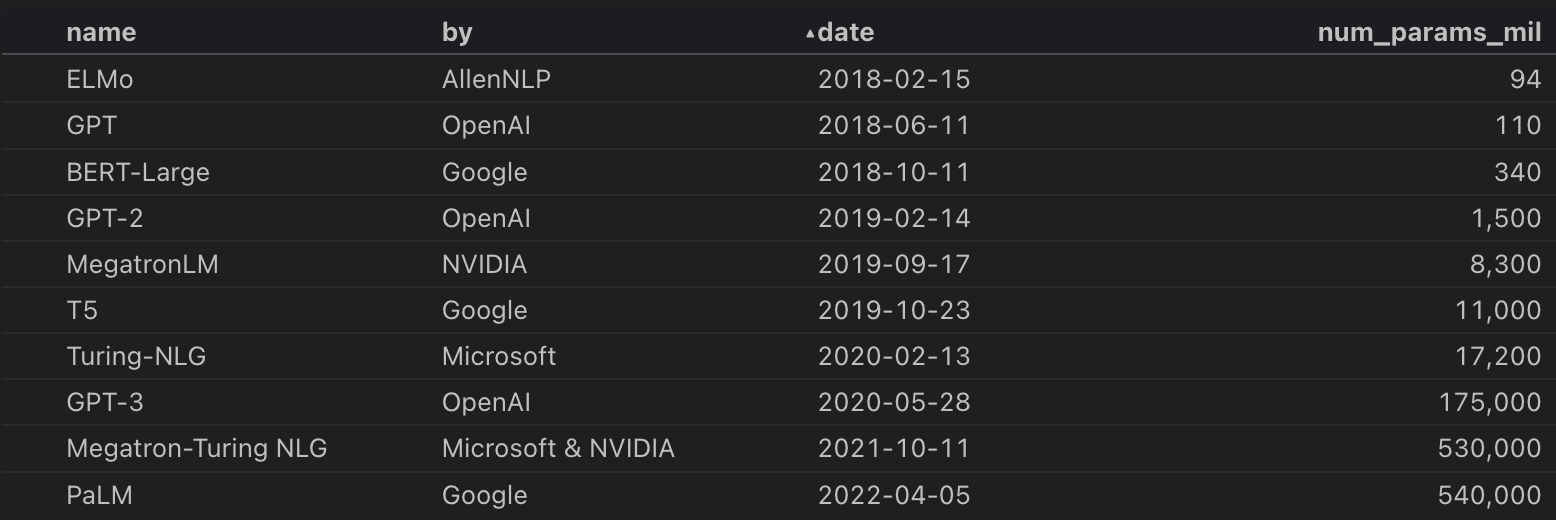
Table 1 - Model sizes of large language models over time from Sorami Hisamoto
What does that mean in terms of cost? PaLM was trained with 6144 TPU chips, the cloud computing cost is estimated to be ~$25M. Just to train the model! That's also only for the final version; there's a lot of iteration leading up to that point. We can also look at the training cost in context of power consumption. It took about 3.2 million kilowatt-hours, or 3.2 gigawatt-hours, to train PaLM. That's equivalent to 0.0001% of US annual power consumption as Tom Goldstein points out (more info in thread):


This is only going to keep increasing. Open AI's next model, GPT-4, is estimated to have 100 trillion parameters! That's a 571x increase over GPT-3 and a 185x increase over PaLM. It’s an utterly massive model. Doing some back of the envelope math, that means it would potentially cost 592 million kilowatt-hours to train GPT-4. That's equivalent to 0.0185% of the US annual power! I’ll discuss some of these energy implications in a later post.
The size of these foundation language models is increasing exponentially and in turn so is the computational cost. Academics, startups, and even most businesses cannot afford to spend $25M, let alone $1M, on computational costs for a single training cycle of a model that might work. This effectively puts the creation and research of large language models out of reach for all except those with the deepest pockets and know how. This training cost alone is a forcing function for companies to buy a solution from foundation model vendors as opposed to building their own models. If you want to dig deeper on the impacts and future of increasingly large language models you can read this short paper on some of the other cost drivers.
Data Acquisition
The compute costs are huge for these foundation models and part of that driver is the amount of data that needs to be processed. As I wrote about in a previous post, data is a competitive advantage in AI. Which means you either need to have more data or higher quality data to do well. What's a baseline for more data? GPT-3 was trained on ~560TB of data. As seen in Table 2, GPT-3 was trained on nearly 500 billion tokens (word components and pairs).

Table 2 - Training Data for GPT-3 from Wikipedia
A majority of the data used to train GPT-3 came from a data source called Common Crawl. ChatGPT (which relies on a version of GPT-3) is using data from as late as August 2021 from Common Crawl. Common Crawl states:
The crawl archive for July/August 2021 is now available! The data was crawled July 23 – August 6 and contains 3.15 billion web pages or 360 TiB of uncompressed content. It includes page captures of 1 billion new URLs, not visited in any of our prior crawls.
Essentially, GPT-3 is trained on most of the data on the internet. So while a large amount of the data used in GPT-3 may be publicly available, there is also data obtained through partnerships, purchasing, or additional scraping. Each of those acquisition methods has an additional labor cost and a very high time cost component.
Why is time an important cost in data acquisition? If you look at Table 1, you can see that the time from GPT-2 to GPT-3 was about 15 months. During that time the model size increased two orders of magnitude. So, if takes normally takes 3-9 months to acquire the necessary data, you are burning up a quarter to half of your available time. You still have to develop a system that can compete with the next generation of models. You’ll be falling behind at an exponential rate since during that time you can be sure that the top players are also acquiring more data. You need talented people that can acquire more or better data in more innovative ways to stay on top.
Talent Cost
It's pretty well known that talent for AI is both expensive and high impact. The first question is what size team is needed to create a foundation model and what do they cost? The number of engineers and AI researchers that authored the paper on GPT-3 is 31. This top-tier talent can typically command between $500,000 to $1,500,000 in total annual compensation each. Taking an average, that's roughly $31,000,000 per year to run the team to create a foundation model. Not many companies can do this, and the ones that can attract top-tier talent are even fewer. Why are they paid so much? These individuals bring enormous exponential value to an organization and they have skills that are in low supply in the labor market. Specifically, these teams need to be able to the following extremely well:
develop novel, cutting-edge algorithms
create robust distributed data systems
acquire massive amounts of quality data
data quality checking at scale
perform distributed model training
transform and vet data at scale
develop novel workflows that resolve issues other companies don't have
Acquiring this kind of talent also requires providing a project that has big implications for the world. These individuals want to work in teams with similarly talented individuals to help push each other to new limits in an environment that promotes innovation. If you want to create a new foundation model but don't have the ability to hire a large, high performing team, you need to have a new approach or access to critical data no one else has.
If you have a new approach, there's the potential to create a much better model and that would be catnip to top talent. How do I know there is room for better models? The brain uses about 12 watts of power. If you say that the brain matures at 25 years of age, then up to that point the brain has consumed 2628 kilowatt-hours of energy. Even though it cannot do all the tasks that a brain can, let's assume PaLM is capable of performing similar to a 25-year-old human brain. PaLM used 3.2 million kilowatt-hours to complete training, approximately 1217x more in energy consumption than the human brain for less than a similar amount of performance. That means there's about three orders of magnitude multiplier improvement that can be made in AI models from a better model structure.
If you have critical data no one else has, then you can build expert systems that others cannot. Current foundation models are general and tend to lack the ability to provide expert advice. If you have access to things like medical data, investment decision data, human mobility information, industrial process data, scientific experiment data, or other difficult to acquire data sets, you are in a good position to either augment an existing model into an expert system or create your own expert system from scratch.
Implications
What do all of these moats mean for you? If you are planning to create your own foundation model you either need to be prepared for large upfront costs or have a technical breakthrough that dramatically reduces both the required data and computational costs. Alternatively, these moats mean it makes more sense to think of generative AI as a utility rather than trying to build your AI system from the ground up. As the famed AI practitioner Andrew Ng has declared, "AI is the next electricity". He meant it more on how AI will be embedded in everything we use, just like electricity is today. Coincidentally, you should also think of AI as being provided to you as a utility in a fashion similar to the way that electricity is provided. If you use this mental model, it has interesting implications for what it means to build businesses with AI and what that means for AI practitioners.
AI and machine learning models will be more about modifying, enhancing, or using generative AI outputs as inputs into other models or functions. People don't use "raw AI" just like they don't use "raw electricity". They convert it into something useful through other processes and forms. Surprisingly, this might make it easier for non-AI practitioners to identify areas of value over AI practitioners, who would prefer to build their own models. Those who will succeed will be able to find other sources of data whether through new instrumentation, partnerships, or acquisitions to act as a differentiator upon the standard utility output.