


The Deception of Averages
On dinosaurs and shifting blobs


No man was ever so much deceived by another, as by himself.
-Lord Greville
Averages are weird. You compress a whole bunch of information into a single number, but cause a certain amount of error. I get it - you're trying to evaluate different options and make a decision based on the typical case. However, I see people become too reliant on a single number without taking the greater context into account or diving a bit deeper to understand what drives those numbers. Take the following examples:
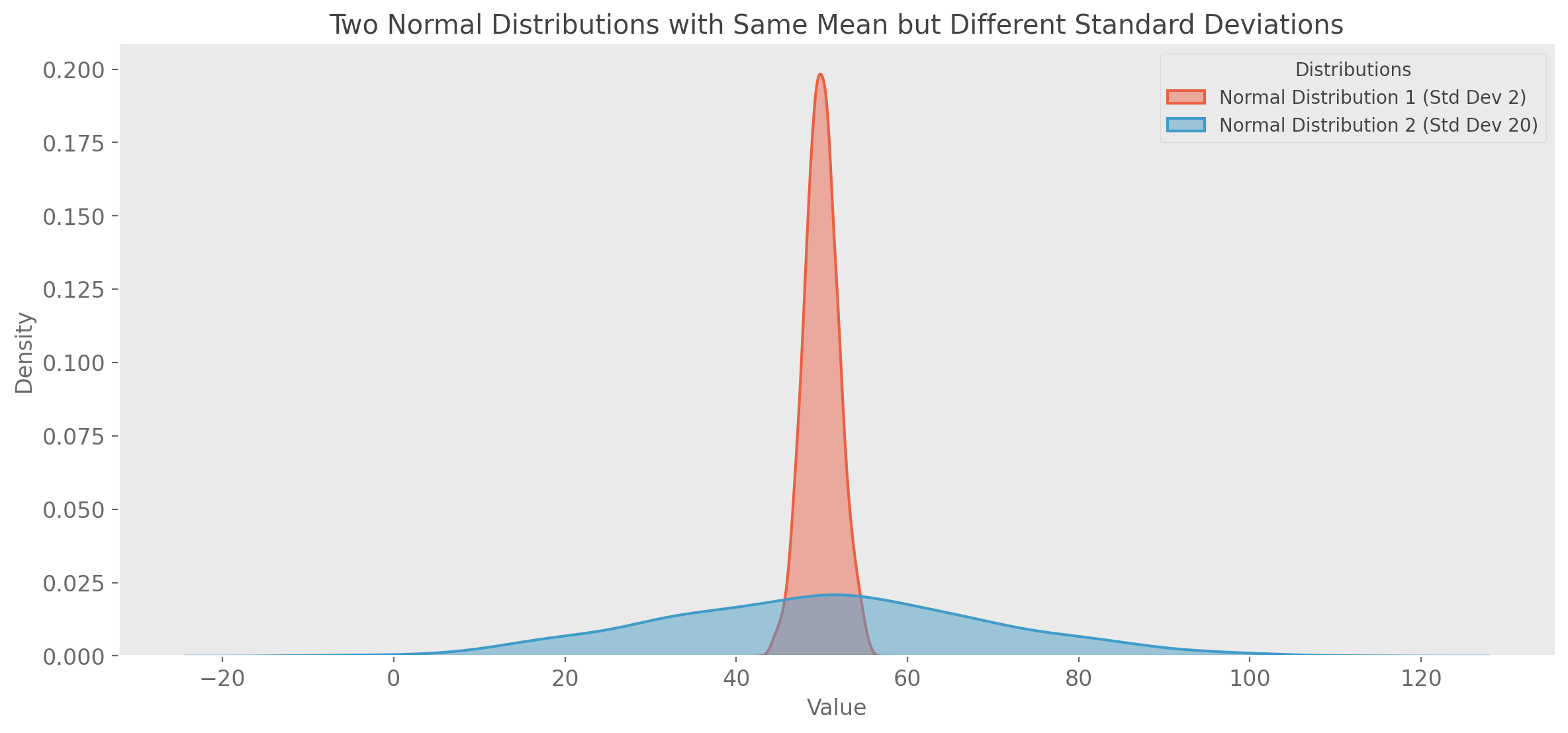
Figure 1. Two distributions with the same mean average value but different standard deviations
In Figure 1 above, both the pink and blue distributions have the same average value (~50). Using the average for the pink distribution will probably be fine for some modes of thought (depending on the context). However, given that the spread in the blue distribution is much greater, if you use the average, you are going to be wrong a lot (again context dependent). This assumes you have a nice normal distribution to use in either case. But what happens with some bimodal like that shown in Figure 2?

Figure 2. A bimodal distribution
The bimodal distribution shown has the same average value as the distributions in Figure 1. However, using the average value will never accurately describe the data above because none of it exist anywhere near the average. A former colleague of mine was fond of saying, "it's like having your feet in the freezer and your head in the oven and calling it room temperature". While the average value may seem reasonable, it doesn't help you make accurate decisions at all. And that's what we're trying to do with analysis of data in the first place - make quality decisions.
When you start doing any sort of modeling, one of the first important teachings is to visualize your data. This is important because summary statistics such as averages, standard deviations, kurtosis, and the like can be deceiving. There's a lot of detail in the data that tends to be hidden, obscured, or otherwise misleading if you don't drill down a bit further. One only needs to look at Anscombe's quartet to understand why.


Figure 3. Anscombe's Quartet (top) and associated summary statistics (bottom). Courtesy of Wikipedia.
Anscombe's quartet is a combination of four constructed datasets that are fundamentally different (as can be seen in the graphs) yet each of them have the exact same summary statistics. When I first saw this many years ago, it blew my mind. It's why all statistical modelers are instructed to visualize their data. You would take vastly different actions in each of the scenarios above. Scenario 1 (top left) is fit well just with some scatter and is likely what people are expecting. Scenario 2 (top right) is a non-linear response and if you use the linear regression line, the error will keep increasing the farther you go on the x-axis. Scenario 3 (bottom left) is really a line of a different slope with an outlier that should (probably) be ignored. Scenario 4 (bottom right) is probably the least expected where the removal of a single outlier yields a vertical line.
But wait, there's more! I previously wrote about how AI bots can affect public discourse by flying under the radar. This happens by making the AI bots appear normal on the surface while infrequently altering only one or two attributes. In my article I created a quick example manually, kind of how Anscombe created his dataset above. However, you can create algorithms to generalize the method for automation. Researchers Justin Matejka and George Fitzmaurice at Autodesk, created a way to generalize Anscombe's approach to modifying data while maintaining the same summary statistics. With it they were able to make a Datasaurus along with other "pictures".

Figure 4. Summary photo of Same Stats, Different Graphs
Just like Anscombe's Quartet, each of the plots from Matejka and Fitzmaurice has the same summary statistical properties while being vastly (and humorously) different. It's a bit crazy to realize that there's an excessive amount of data topologies that can result in the same summary statistics. What we learn here is that summary statistics are not great at telling the actual story nor accurately describe the topology of the data.
To reiterate the point, visualizing your data is extremely important. When you have many dimensions (or variables) of data, finding ways to understand the interactions is paramount. However, even if you visualize the data, you can't account for lots of dimensions interacting at the same time. High-dimensional space is unintuitive. That's why we build models, particularly of the machine learning variety, that can handle complex non-linearities and interactions.
Data and AI
What does this all have to do with AI? Well for one, machine learning models were created to deal with shifting dynamics and to be able to interpret different data topologies. However, it's good to understand that when AI models make a prediction, they are still predicting a value that is average-like in that it attempts to reduce error on training data for the given loss function based on all of the non-linear interactions from the variables it has access to. It's why there's a big focus on reducing inference error, particularly when weighted by impact.
At the same time, data is the fuel that makes AI run. How well data is labeled along with the purity (or lack of noise) contained within can affect not only how well models are trained but also how well they are evaluated. We need to look no further than a model that just came out from Adept.AI called Fuyu-8B. While many people may be discussing how this is a faster transformer since it doesn’t contain an image encoder, looking closer at the announcement there are some interesting points about directly investigating data.

Figure 5. An investigation into data labels for common evaluations sets by Adept.AI
Adept.AI knew their model performed very well but found it wasn't beating some of the existing models on standard evaluation benchmarks. When they looked into it, they found that their model was actually giving correct results but due to the way the data had been labeled, their model was (incorrectly) getting low scores on some of the data. Either the data was mislabeled altogether (right image) or their model was being more specific than the label (left image). This led Adept.AI to create a modified evaluation set with resolved labels so that they could better understand the true performance of their model.
One of the most underrated, unsexy, but high impact activities in machine learning is spending time looking at the actual data samples where your models are having errors. Looking at these error observations can spur you to find insights to modify your inputs (add variables or transformations), change the way you evaluate your models (as Adept.AI did), or alter your modeling approach altogether (find an approach that can actually identify fish). Each of these shifts from random model building to focused tested ways to improve models.
Decision Making
Using data for decision-making is based on the hope that you'll make better decisions with data. However, it can be fairly easy to misapply or misinterpret data and make incorrect decisions. The above discussion on averages hiding information shows this. Ideally, if you are making decisions around the same topic continuously then averages can be informative. That assumes that the underlying distributions are staying the same. Maybe they're changing, maybe they're not. But if you're not looking, how would you know?
The fact that the same numbers can represent wildly different things means that your decision-making process needs to rely on more than just using averages. Maybe you implement QA checks on the underlying information to make sure things haven't shifted from your current mental model. Perhaps you use different visualization techniques. Perhaps you look at the dispersion of errors that would be made if you were to only use the average. There are many, many ways to make decisions besides just using averages. Remember, averages are heuristics and that by their nature, heuristics are shortcuts. That means their use is context dependent and even in the right context they aren't always accurate. Plan accordingly and continuously evaluate your approach.